
C’est avec grande joie que nous postons cette entrée, en effet on arrive à avoir un script fonctionnel
qui répond à la plupart des soucis qu’on a trouvés tout au long de notre projet.
On dit de la joie, parce que pour nous trois, n’ayant pas de fortes bases informatiques, arriver à
comprendre comment ce script fonctionne et pouvoir y ajouter ou supprimer des choses a demandé des
heures et des heures de réflexion, on se réjouit donc d’arriver à ce stade du projet.
Si jamais les personnes des promotions à venir lisent cette entrée, il est important de donner un message
qui rassure. Ce Master est formidable, on apprend énormément de choses. Cependant on est vite
confrontés à beaucoup de nouvelles informations. Vous allez vivre une montagne russe d’émotions :
de l' incompréhension au désespoir, la tristesse puis la fierté. Ne désespérez pas s’il y a des moments de
détresse, avec de la détermination et en y consacrant du temps vous allez parvenir à comprendre et à faire
tout ce qui est demandé. Voyez ! on y est presque !
Dans cette entrée nous allons montrer le script que nous avons travaillé tout au long du semestre pour notre projet
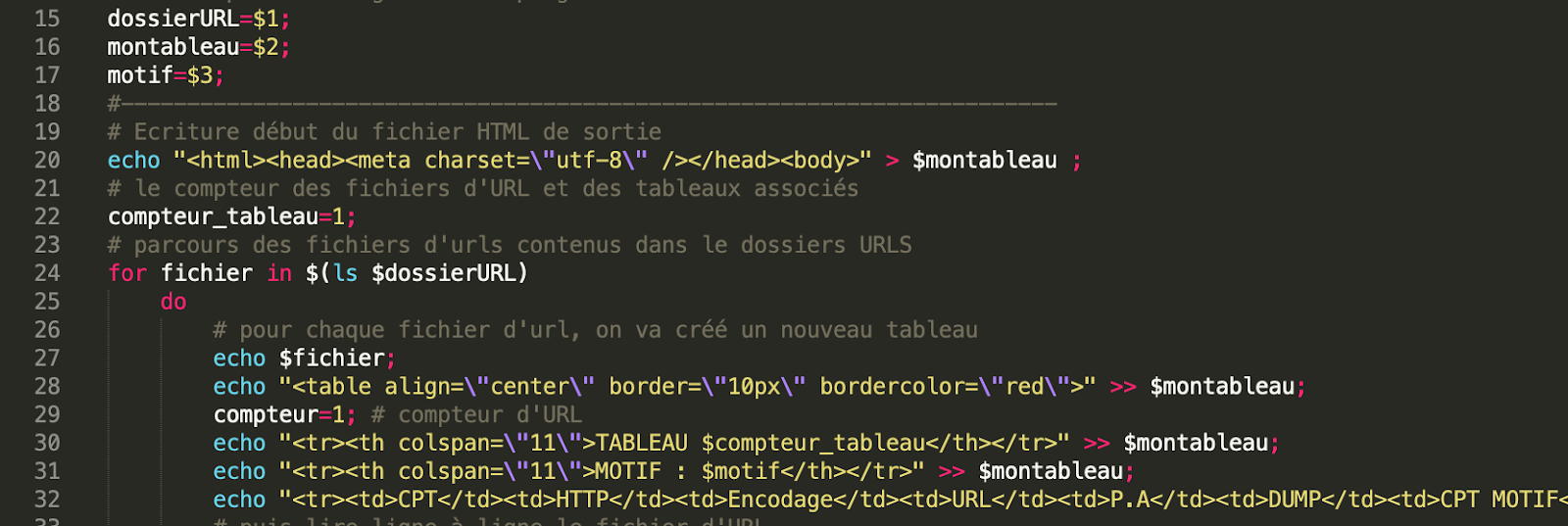
Dans cette première partie nous établissons les fonctions pour les dossiers des URL, pour créer le tableau et pour reconnaître notre motif.
Le premier traitement correspond au fichier URL, pour chaque fichier nous créons un tableau pour les URL’s
Voici quelques captures d’écran des tableaux en espagnol et en français.


Dans cette boucle while on traite nos URL, on met chacune sur une ligne et à l’aide de la commande curl on vérifie la valeur http_code.
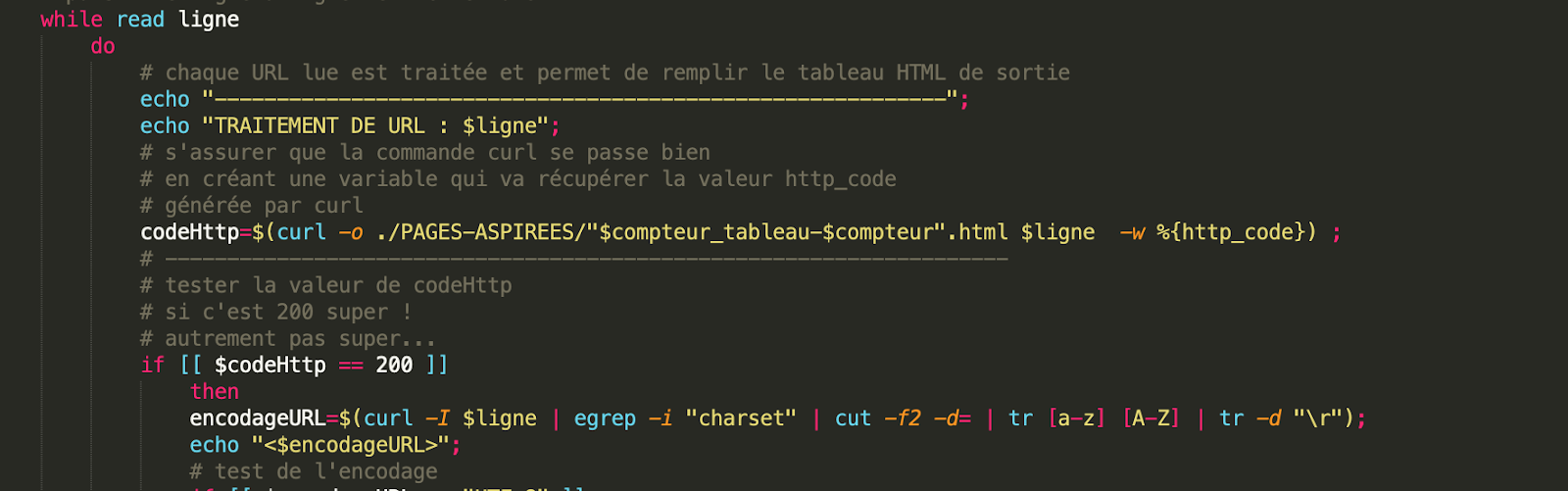
Ensuite, si l'encodage de l’URL est de l’UTF-8 on fait les traitements pour l’obtention de notre corpus.
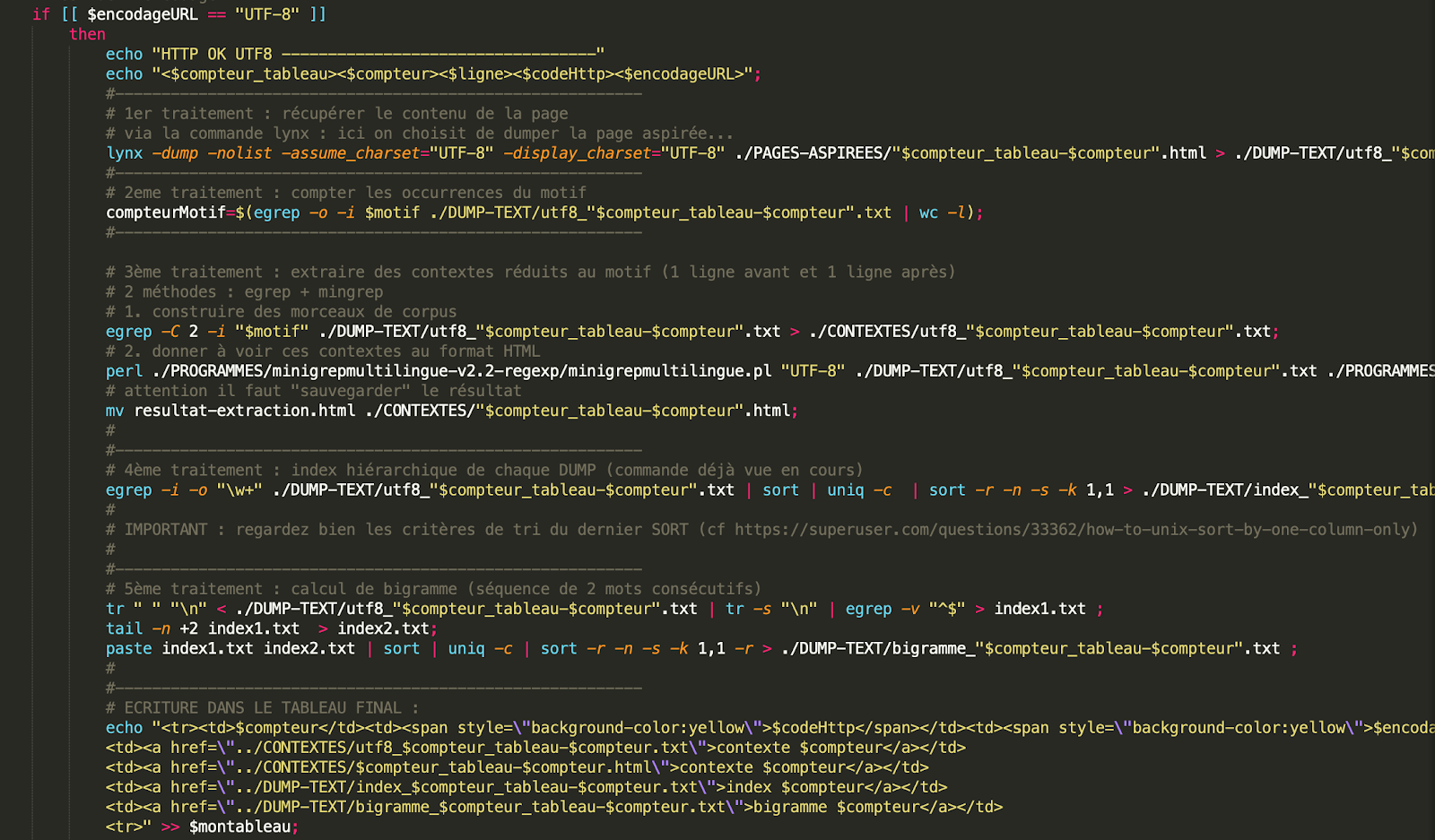
1- On aspire les contenus de nos URL avec la commande Lynx et on les garde dans notre répertoire PAGES ASPIRÉES en format html, et dans le répertoire DUMP-TEXT.
2- On compte les motifs.
3- Dans cette partie on extrait les contextes réduits au motif. Pour cela nous allons utiliser le programme minigrep. (voir l'entrée minigrep pour plus de précisions)
4- On créer les index hiérarchique de chaque DUMP. (pour plus d’infos concernant la création des index consultez les entrées précédentes.)
5- Calcul de bigrammes ( pour plus d’infos concernant la création des bigrammes, trigrammes, fourgrammes...etc, consultez les entrées précédentes
Dans un premier temps, on pensait que le script pourrait s'arrêter ici. Quand on le lançait dans le terminal,
il fonctionnait bien et toutes les informations étaient aspirées. Cependant, on s’est vite aperçu qu’il y avait certaines URL qui n'étaient pas encodées en UTF-8 et par conséquent des mauvais rendus
s’affichaient sur notre tableau et sur nos fichiers DUMP.
Pour remédier à cela, un autre traitement a été intégré :

Si l’encodage identifié par l’option curl n’est pas UTF-8 on va le convertir en utilisant l’option bash iconv.
Cette option est très utile, pour l’utiliser sur un fichier vous tapez :
iconv -f [fichier1] -t [fichier2] (f=from t= to) iconv -l pour afficher la liste d’encodages disponibles.
Ensuite, on fait les 5 traitements évoqués précédemment.
C’est fini ? pas encore. Il se peut que, même en ayant utilisé l’option curl et modifié avec iconv, il y ait
encore de sites avec des encodages non reconnus. Une autre option s’avère donc efficace pour y remédier : Perl.
Pour que ce traitement intégré au script fonctionne, il est nécessaire de télécharger le programme detect
encoding et de le placer dans le répertoire PROGRAMMES.
Avec cette partie de script on pourra identifier l’encodage de l’URL et faire le traitement correspondant
avec iconv.
Quelques précisions seront ajoutées concernant le script utilisé pour traiter les URL en japonais.
Commentaires
Enregistrer un commentaire