
Donc pour revenir à toute ces histoires d'URLs, la commande lynx nous permet de les récupérer tout comme le ferait la commande wget à l'exception que lynx nous permet d'obtenir une page Google dans un format texte.
La commande est donc la suivante:
lynx -dump "URL_de_la_page_google" > banlieues_google.txt
lynx -dump "https://www.google.com/search?q=french+kiss&rlz=1C5CHFA_enFR921FR921&oq=french+kiss&aqs=chrome.0.69i59j0j46j0l2j69i60l2j69i61.12972j1j7&sourceid=chrome&ie=UTF-8" > frenchkissfr_google
Et maintenant que nous en avons extrait, nous pouvons les garder dans un fichier urls, créer à notre première séance:

En tapant less frenchkissfr_google on visualise les résultats :

On veut par la suite récupérer les URL pour les mettre dans un fichier txt. Nous avons recours ici à la fonction egrep. Grâce à cette expression régulière on pourra isoler uniquement les URL de nos fichiers.
récupérer des URL
counter=0; while [ $counter -lt 300 ]; do lynx -dump "https://www.google.com/search?q=french+kiss&rlz=1C5CHFA_enFR921FR921&ei=fZ6NX4q0J5Gkgwf1uK-YDg&start=200&sa=N&ved=2ahUKEwjK5oL96sDsAhUR0uAKHXXcC-M4ZBDy0wN6BAgGEDU&biw=1200&bih=707">> france_french_kiss.txt; counter=$(($counter + 100)); done
base) oscarme@MacBook-Pro-de-Oscar URLS % for lien in $(egrep "^ +[0-9]+\. https\://www\.google\.com/url\?q\=" france_french_kiss.txt | cut -d"=" -f2 | cut -d"&" -f1 | egrep -v google | egrep -v youtube); do echo "==$lien=="; done>> URL_france_frech_kiss
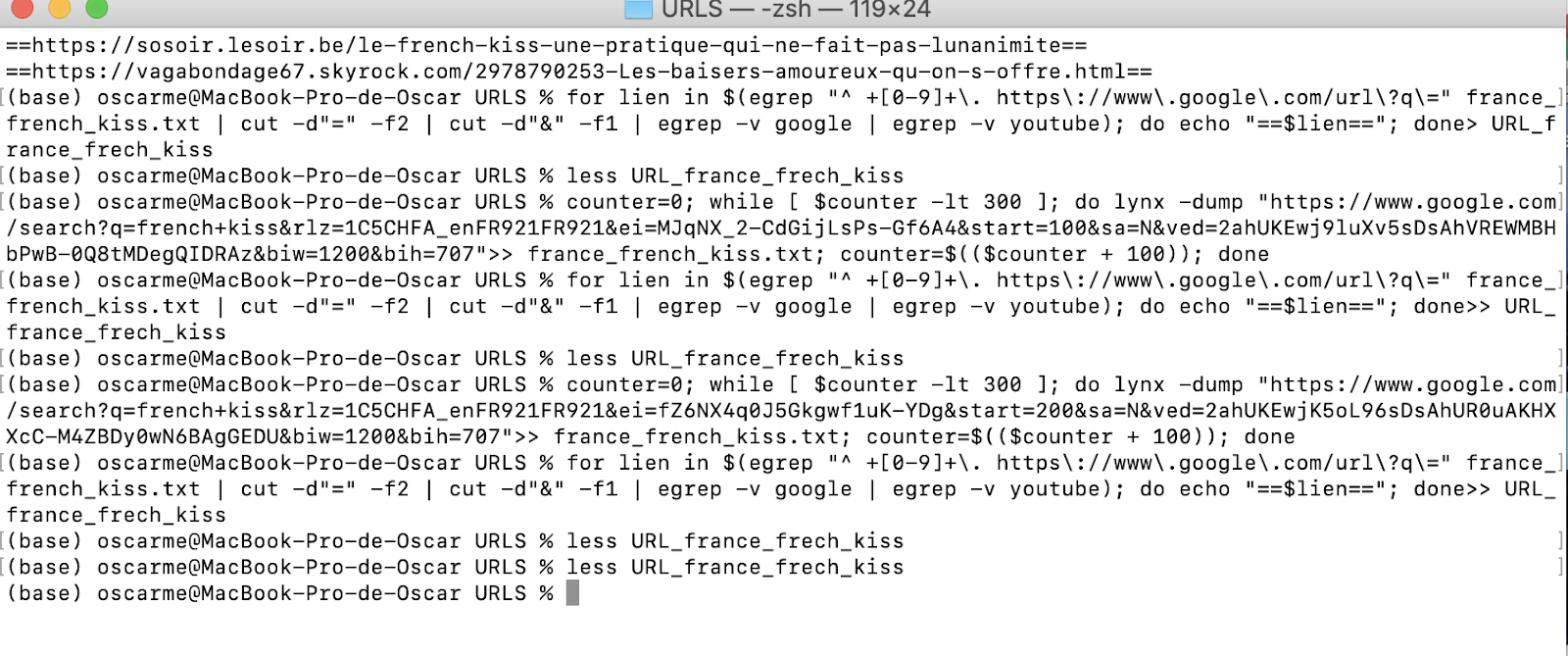
Pour obtenir les URL on a utilisé deux commandes qu’on apprises lors du cours Corpus Linguistics. Première commande:
counter=0; while [ $counter -lt 300 ]; do lynx -dump "https://www.google.com/search?q=french+kiss&rlz=1C5CHFA_enFR921FR921&ei=fZ6NX4q0J5Gkgwf1uK-YDg&start=200&sa=N&ved=2ahUKEwjK5oL96sDsAhUR0uAKHXXcC-M4ZBDy0wN6BAgGEDU&biw=1200&bih=707">> france_french_kiss.txt; counter=$(($counter + 100)); done
counter=0; while [ $counter -lt 300 ]; do lynx -dump "https://www.google.com/search?q=galocher&rlz=1C5CHFA_enFR921FR921&ei=paeNX4yQIom4a_2FitgN&start=100&sa=N&ved=2ahUKEwjM9tfa88DsAhUJ3BoKHf2CAtsQ8tMDegQICBAz&cshid=1603119269226407&biw=1200&bih=707">> france_galocher; counter=$(($counter + 100)); done
https://www.google.com/search?q=galocher&rlz=1C5CHFA_enFR921FR921&ei=1qeNX_L6A4WKasvasfgH&start=0&sa=N&ved=2ahUKEwjyvejx88DsAhUFhRoKHUttDH84ZBDy0wN6BAgGEDI&biw=1200&bih=707
Grâce à cette commande on peut récupérer les 3 listes de résultats de notre recherche ( sur google on a configuré le site pour avoir une liste de 100 résultats et on en a obtenu 3). Cependant cette commande prend tout le texte source.
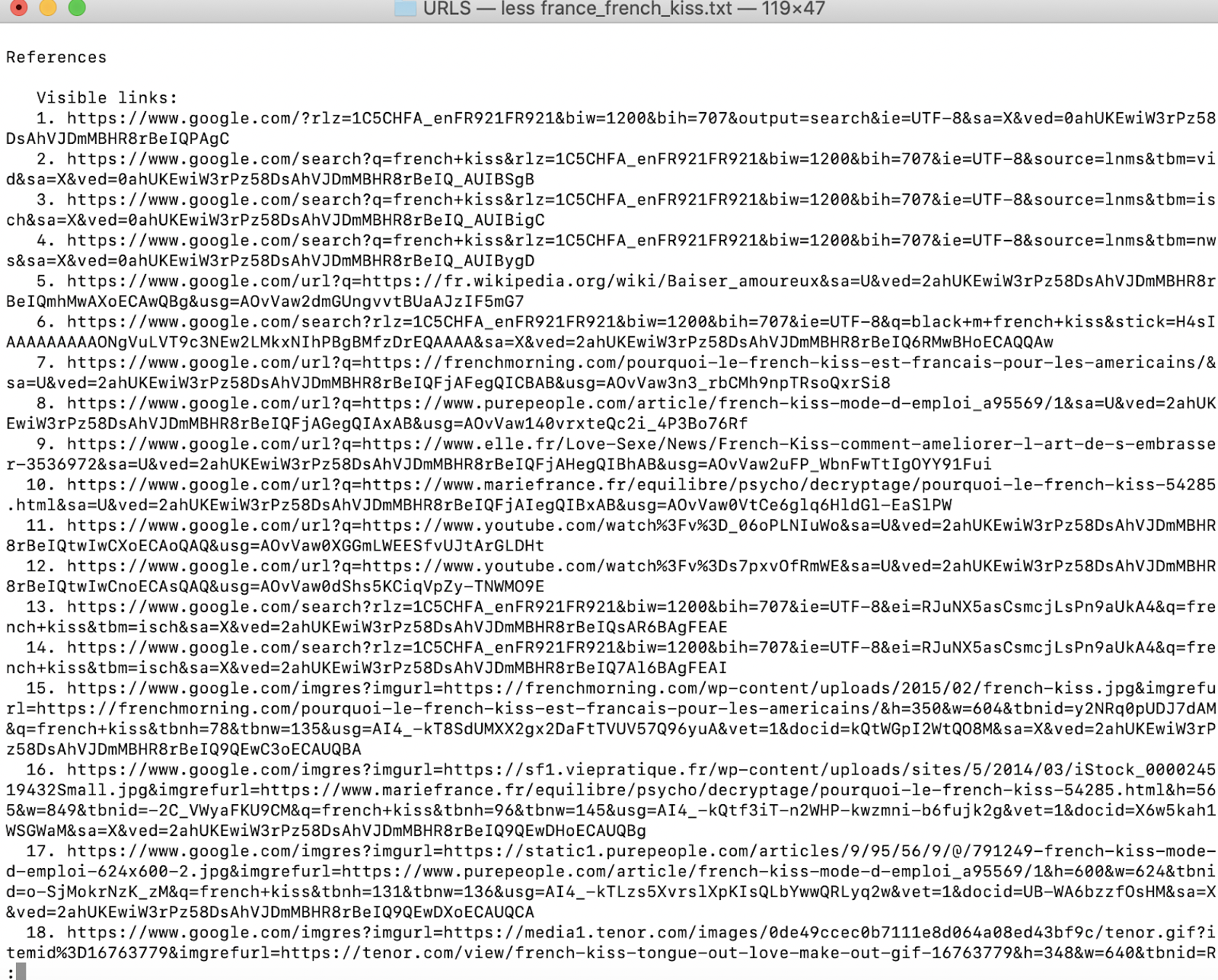
pour trier un peu les informations reçues on utilise une deuxième commande
for lien in $(egrep "^ +[0-9]+\. https\://www\.google\.com/url\?q\=" france_french_kiss.txt | cut -d"=" -f2 | cut -d"&" -f1 | egrep -v google | egrep -v youtube); do echo "==$lien=="; done>> URL_france_frech_kiss
Si on décortique un peu cette commande (ce que l'on y comprend du moins, pour l’instant) la fonction egrep permet de rechercher et imprimer les lignes qui correspondent aux patron donnés.
Elle admet des expressions régulières. Justement la première ligne en comporte quelques unes. ^=chercher tout saut ^+[0-9]
Il nous aurait été préféré de pouvoir décortiquer et expliquer plus en détail cette commande mais les connaissances en regex restent encore très basique (toujours pour l’instant !), mais ca va changer très vite, puique nous avons la chance d'avancer dans ce thème dans plusieurs cours notamment celui de langages réguliers.
On obtient la liste des URL en format .txt. On a tout de même constaté que certaines URL se répètent. Pour l’instant nous ne disposons pas de solution à ce problème. Nous y reviendrons plus tard.
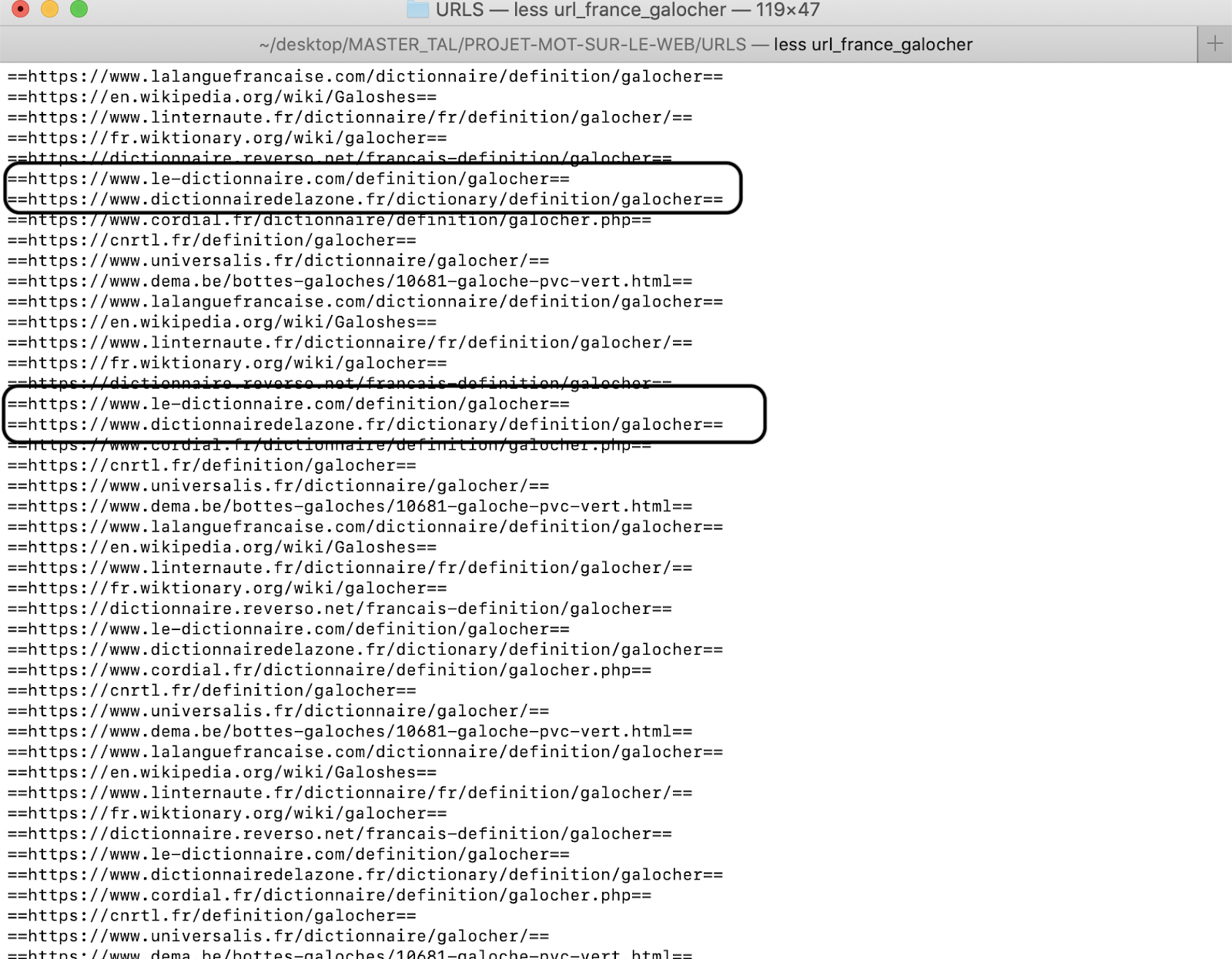
Pour continuer avec l’obtention des URLs nous allons essayer avec une autre commande bash. Nous l’avons travaillé dans le cours de corpus linguistics (petit clon d'oeil et merci à M. Daube). La nouveauté de cette commande c’est qu’elle nous permet de récupérer tous les résultats sur google grâce à l’option “counter”. Nous ne devons plus faire le traitement de résultats page par page. Sympa !
La session suivante sera d'autant plus intéressante que nous aurons entre nos mains de bons début de d'extraction accompagné de traduction, par langue!
Commentaires
Enregistrer un commentaire