Un beso con lengua, Frencher!
Dans cette partie, il sera montré quelques résultats par pair de langue
Nous allons commencer par présenter nos recherches en espagnol, et en français.
Petite remarque avant de continuer plus loin : en espagnol, le terme "French Kiss" se traduit en espagnol par "Beso con lengua".
Il sera donc ici détaillé la façon dont on a procédé pour "Beso con lengua":
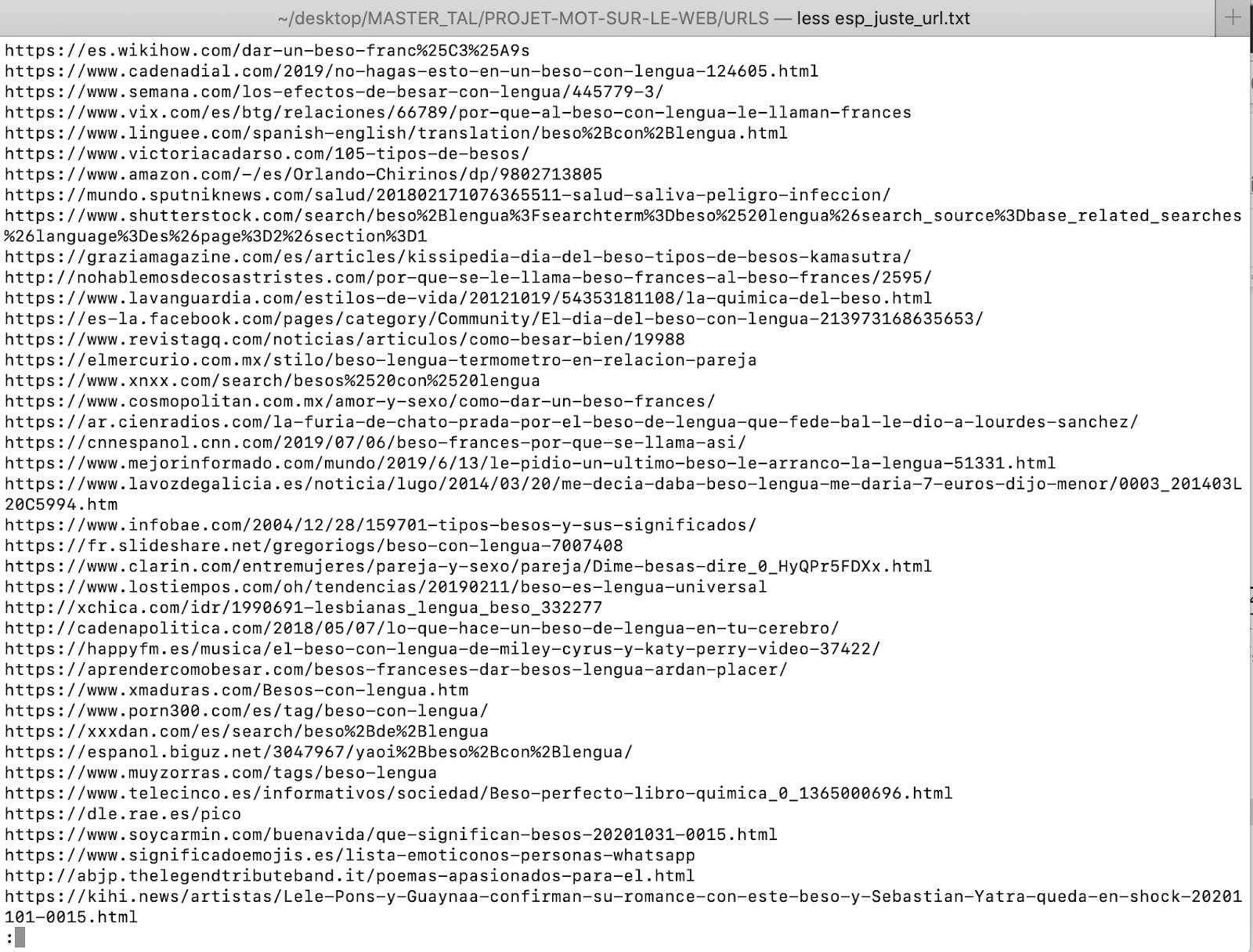
La première commande est pour trouver les URLs en espagnol du mot "beso con lengua" ou son autre version aussi trouvé : "beso francés".
Pour le cas de "beso con lengua"
Commande :
counter=0; while [ $counter -le 300 ]; do lynx -dump "https://www.google.com/search?q=suburbs&client=ubuntu&channel=fs&biw=1494&bih=657&sxsrf=ALeKk011piWSj9r1StcMMmaC2Fwkb8FqNg:1603092362766&ei=ij-NX7-dLquJjLsPzLqSsAw&start=$counter&sa=N&ved=2ahUKEwi_isy2kMDsAhWrBGMBHUydBMY4FBDy0wN6BAgWEDM">> mes_liens_bruts.txt; counter=$(($counter + 20));done
on obtient donc :
A présent, on cherche à trier ce fichier .txt. Pour ce faire, la commande egrep sera d'une grande aide :
egrep "^ [0-9]+\." url_esp_beso.txt | cut -d"=" -f2 | cut -d"&" -f1 | egrep "^http[s]?" | egrep -v google > esp_juste_url.txt
Voici le résultat :
Pour "beso francés" :
counter=0; while [ $counter -le 300 ]; do lynx -dump "https://www.google.com/search?q=beso+franc%C3%A9s&rlz=1C5CHFA_enFR921FR921&ei=VBSgX8uNCMOMlwTcuqCoDQ&start=$counter&sa=N&ved=2ahUKEwjLh8PxheTsAhVDxoUKHVwdCNUQ8tMDegQIBBA0&biw=1200&bih=707">> beso_frances_url.txt; counter=$(($counter + 20));done
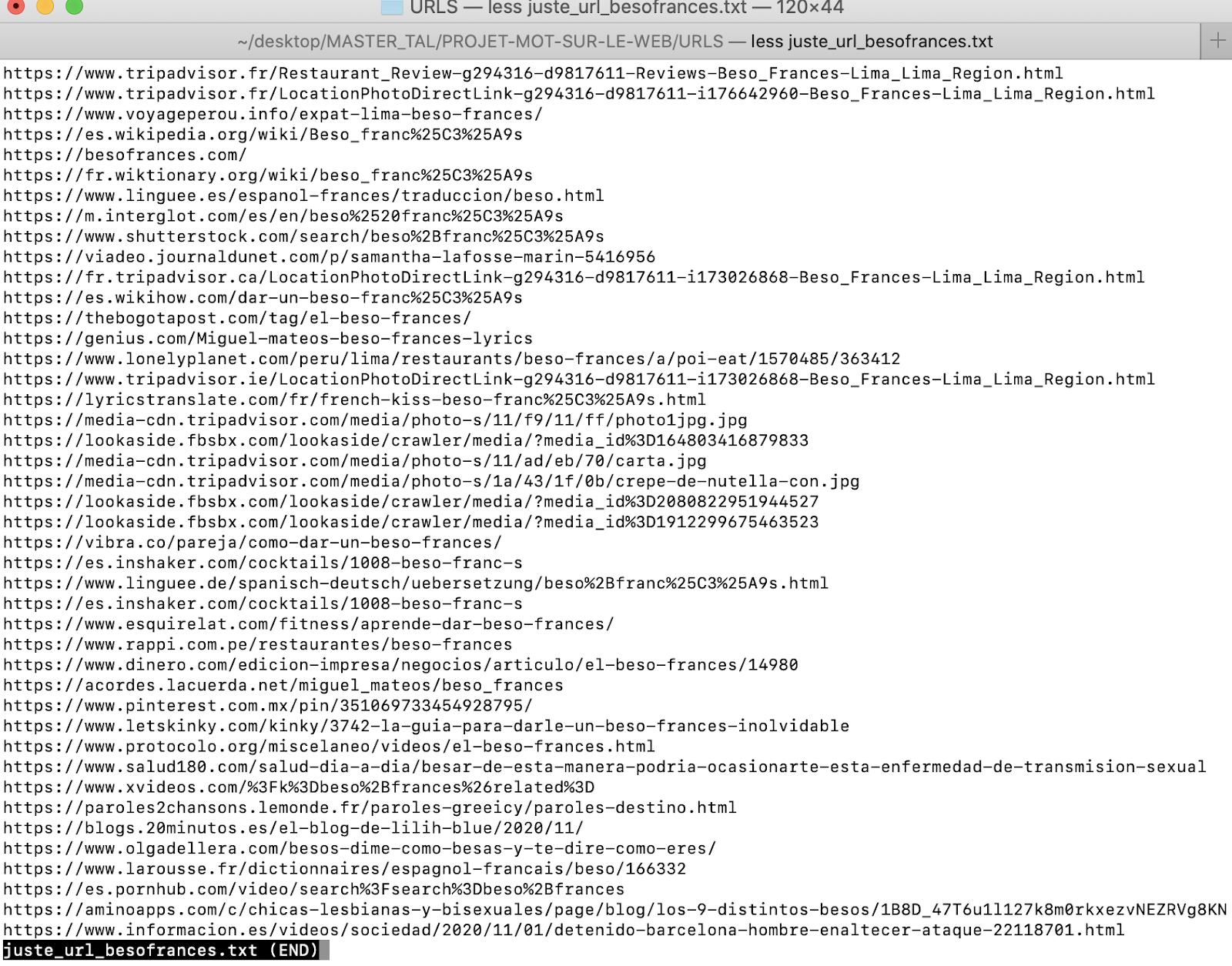
Voilà la liste des URLs obtenue :
Passons donc aux URLs pour la version française du mot. Notre mot, comme vous le savez, c’est “french kiss”. Nous avons également trouvé un équivalent en français “galocher”. Même si ce n’est pas exactement la même signification, puisque ce mot provient d’un registre plus oral et donc informel. Nous trouvons ça tout de même intéressant d’en obtenir les URLs. Cela pourrait en effet enrichir notre corpus. Par ailleurs, il est intéressant de noter que le terme "french kiss" n'existe pas de façon formel dans les dictionnaires français, et la seule équivalence trouvée, se trouvait dans le dictionnaire en ligne du Petit Robert.
D’autre part, nous nous sommes aussi intéressés au terme Frencher. Mot utilisé dans la province de Québec au Canada.
Pour French Kiss:
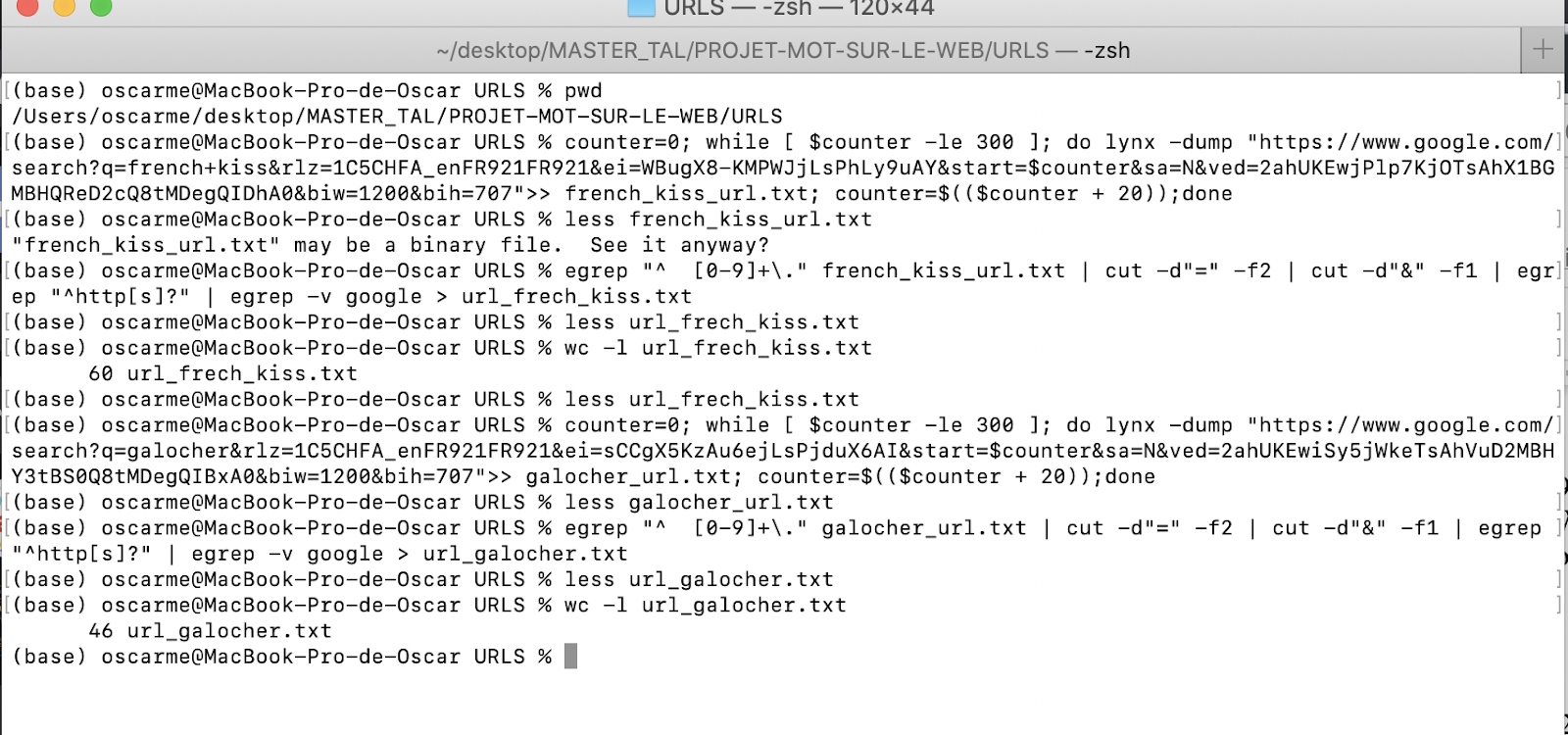
counter=0; while [ $counter -le 300 ]; do lynx -dump "https://www.google.com/search?q=french+kiss&rlz=1C5CHFA_enFR921FR921&ei=WBugX8-KMPWJjLsPhLy9uAY&start=$counter&sa=N&ved=2ahUKEwjPlp7KjOTsAhX1BGMBHQReD2cQ8tMDegQIDhA0&biw=1200&bih=707">> french_kiss_url.txt; counter=$(($counter + 20));done
Voici la liste de commandes.
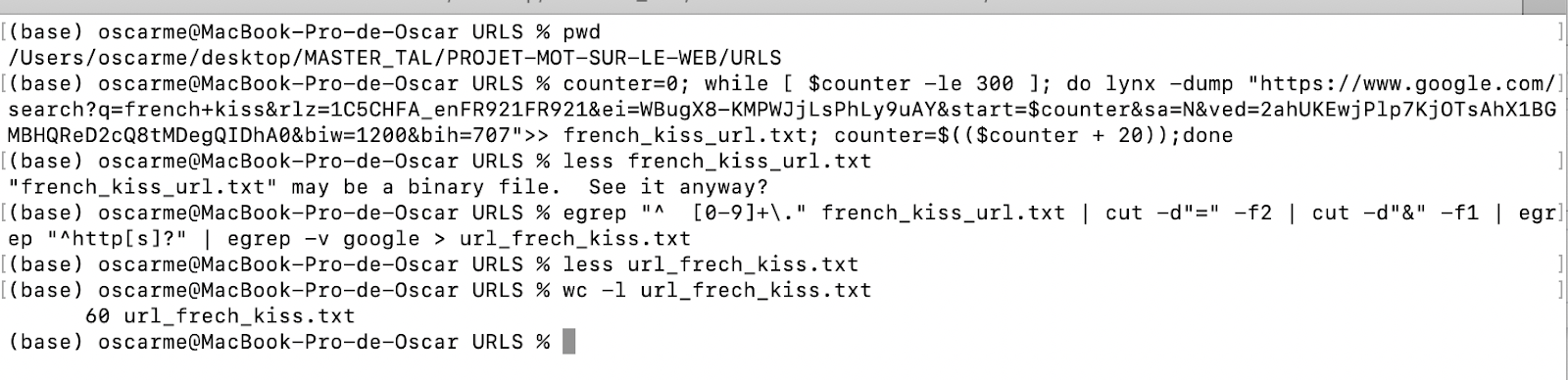
et les résultats :

Pour Galocher :
Liste de commandes :
Liste des URLs :
Dernier Script du 18.11.2020
Dans le dernier script nous avons ajouté des commandes qui nous permettront d’obtenir les bi-grams, tri-gram- four-grams dont nous avons besoin pour notre analyse.
Cependant, il est important de connaître d'où vient cette information, que notre script obtient, bel et bien automatiquement.
Allons- y.
Le site internet nous montre comment le faire avec une des pages aspirées. Cependant, pour nous c’est plus pertinent de le faire avec le corpus en entier que nous obtenons à l’aide de commandes suivantes (rappel)
J’obtiens mes URLs:
counter=0; while [ $counter -le 300 ]; do lynx -dump "URL" >> url_french_kiss.txt; counter=$(($counter + 20));done
Je les nettoie :
egrep "^ [0-9]+\." url_french_kiss.txt| cut -d"=" -f2 | cut -d"&" -f1 | egrep "^http[s]?" | egrep -v google > liste_url_french_kiss.txt



Commentaires
Enregistrer un commentaire