
Itrameur
Dans cette entrée nous partagerons nos commentaires sur la prise en main de l’outil Itrameur. Nous
avons intégré le corpus et vérifié que la segmentation était bien définie par les balises du corpus. les
rectangles ne se croisent pas et toutes les parties semblent y être.
Après avoir importé le corpus dans le logiciel, nous nous sommes rendus compte que l’analyse était
faite mot par mot et que dans notre cas (french kiss) on avait deux mots, voire trois en espagnol. Que
faire ? La solution a été de remplacer les occurrences des mots french kiss, French Kiss, “French
Kiss” “french kiss” en un seul mot : french_kiss. Même traitement pour l’espagnol et le turc
beso_con_lengua, fransız_öpücüğü. cela a bien fonctionné.
Dans un premier temps on s’est intéressés à l’indice de fréquence du mot dans notre corpus. On
apprend qu’il y a 255 occurrences.

Ensuite on s’est intéressé aux cooccurrences du mot. Ce tableau nous montre un premier résultat.
On voit qu’il y a des mots qui “polluent” notre résultat, notamment les stops words. Pour éviter cela,
vous allez dans trame/dictionnaire/selection. Vous cochez les mots à ne pas afficher lors du calcul de
cooccurrences.
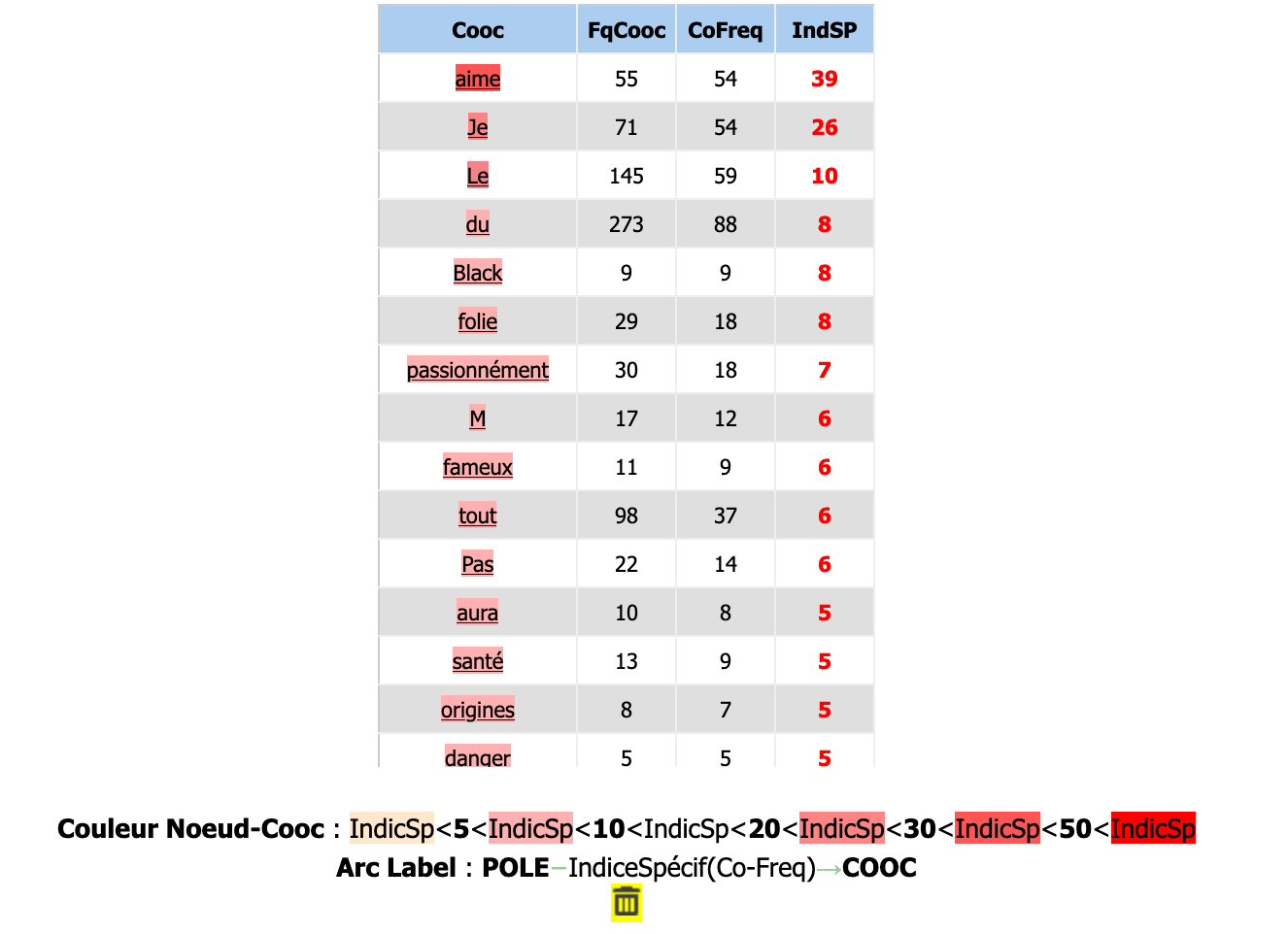
Nous avons repéré qu’un des co référents le plus saillant est Black et M, le chanteur. En effet, il a
une chanson intitulée french kiss qui a eu apparemment pas mal de succès en France. De même, le
mot “aime” est très fréquent car il est assez présent dans les paroles des chansons. On réfléchit à le
laisser ou le supprimer de notre liste. Après avoir analysé le concordancier on confirme qu' aimer
correspond presque 100% aux paroles. On va donc s’en passer. On a déjà Black M dans nos résultats.
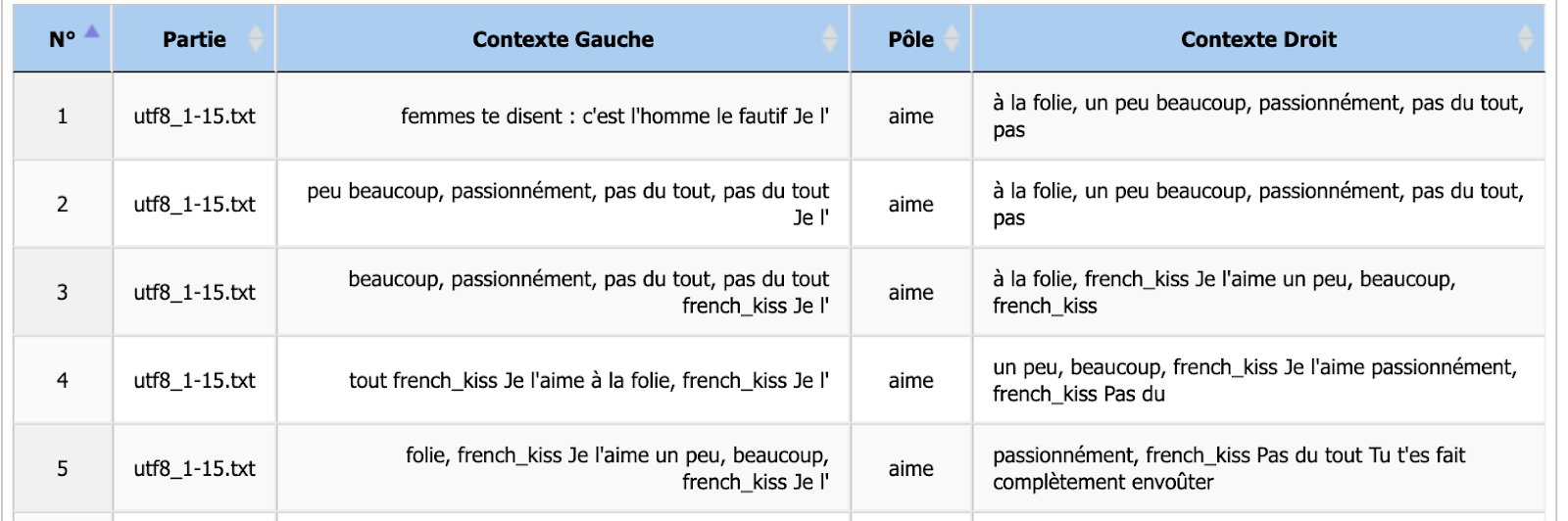
Voilà, c’est un premier aperçu des analyses effectuées sur Itrameur. Vous aurez accès à l’analyse
complète de toutes les langues lors de la mise en ligne de notre page web.
Commentaires
Enregistrer un commentaire