
Concaténation et nettoyage du corpus.
Cette partie de concaténation et nettoyage de corpus est clé car elle va alléger notre corpus pour pouvoir
l’analyser sur Itrameur.
Pour ceux qui travaillent sur Windows, un programme pour concaténer est disponible sur icampus.
Il suffit de télécharger le Fichier + le programme concat et de les placer dans le même dossier.
Double click pour le lancer et cela concatène les fichiers existants dans ce répertoire.
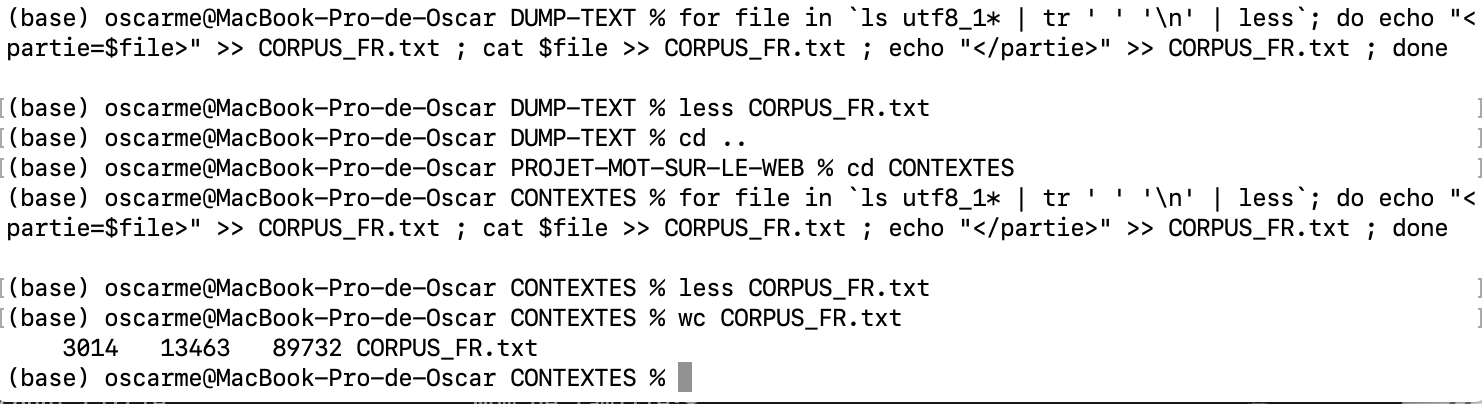
Si ce n’est pas Windows, comment faire? Sachant qu’il faut introduire une valise au début et à la fin
de chaque fichier DUMP txt et CONTEXTES txt, nous avons appris en cours cette commande.
for file in `ls utf8_1* | tr ' ' '\n' | less`; do echo "<partie=$file>" >> CORPUS_FR.txt ; cat $file >> CORPUS_FR.txt ; echo "</partie>" >> CORPUS_FR.txt ; done
En utilisant cette commande la concentration se fait facilement. Pensez à vous placer dans le
répertoire DUMP avant de la lancer. Même procédure dans le répertoire CONTEXTES.
Nettoyage
Après la concaténation, il faut penser au nettoyage du corpus. Il faut que les valises existantes ne
servent qu’à marquer la transition de chaque fichier. (début et fin de partie). Il est donc important de
supprimer les valises ou chevrons issus des URLS. On peut le faire avec l’option rechercher et
remplacer de votre éditeur de texte. Mais, n'étant pas l’option la plus souhaitable, nous avons
essayé de le faire avec les commandes bash sed et tr
Après avoir parcouru notre corpus, on s’est vite aperçu qu’il fallait surtout supprimer les balises
HTML, les menus, les liens vers d’autres sites, les liens réseaux sociaux, images et vidéos.
Nous avons utilisé la commande tr -d. Celle- ci nous a permis d’effacer certains mots très fréquents
mais inutiles pour notre analyse. Voici quelques exemples :
tr -d '(BUTTON)'
tr -d '(IFRAME)'
tr -d '(Facebook)'
Ensuite nous avons fait appel à la commande sed (gsed sur Mac).
gsed -r 's/^ *//g' < CORPUS.FR.txt : Supprimer les espaces et les tabulations au début de ligne :
gsed -r 's/^\*.*//g' < CORPUS.FR.txt : Supprime les lignes commençant par *, nous avons fait la même pour les symboles “+” et “ ०”
Vous visualisez les modifications faites par sed sur l’écran pour ne pas modifier le fichier, pensez à
en créer un nouveau fichier si le résultat vous convient.
Cela fonctionne bien mais en parcourant notre corpus on s’est rendu compte que certaines de lignes
qui commencent par “*” comportent des phrases avec le motif recherché.
Après ces quelques petites commandes il restait encore des morceaux de menus, des liens vers
d’autres URLs, des liens des images, etc.. Nous avons donc décidé de terminer notre nettoyage
à la main. Ce n’est pas remarquable, mais au moins nous avons pu mieux nettoyer le corpus.
PS: Quand vous modifiez des fichiers il est recommandé de créer un fichier de backup au cas où.
Commentaires
Enregistrer un commentaire